How we approach forward deployed engineering | by Hamnaghufran | May, 2026
11 min read
·
May 24, 2026Press enter or click to view image in full size
Companies increasingly adopt forward-deployed engineering (FDE) teams to accelerate development while staying aligned with internal workflows. But what actually happens when an external engineering team integrates into an organization?
Bringing in an external engineering team does more than add capacity. It directly influences how internal engineers collaborate, contribute and take ownership of systems. This matters because modern software development depends heavily on coordination and shared responsibility.
Research in software engineering highlights how engineers divide their time between collaboration and independent work. Leslie Perlow reports that software engineers spend about 30 percent of their time on interactive activities and 60 percent working alone. In this environment, forward-deployed engineering teams work alongside internal teams instead of operating independently.
This article explores how forward-deployed engineering teams integrate into organizations, from initial onboarding to production delivery, and outlines what teams can expect at each stage of the process.
Why most FDE descriptions miss the point
- “Your team will own the system.”
- “Knowledge transfer is built into the engagement.”
- “Our engineers work side by side with your team.”
These statements can raise valid concerns. Research shows that only about 31 percent of software projects succeed in terms of on-time and accurate deliveries. Many failures stem from unclear requirements and a lack of visibility into how work happens.
What evaluators actually need to know
When a technical leader is seriously considering forward-deployed engineering, the questions usually become much more specific.
For instance:
- Who writes which parts of the code and at what stage of the project?
- At what point does the internal team move from observing to leading development?
- What does progress actually look like halfway through the engagement?
- What new capabilities should the internal engineering team have by the end?
Engineering teams want to figure out what their team will truly learn during the process or simply watch an external team build a system. They want to understand whether the engagement creates long-term capability or just short-term results.
The FDE model in practice
Consider a company aiming to build an AI-powered internal system designed to automate document classification using machine learning. The objective is to enable teams to process thousands of documents ежедневно with greater speed and accuracy.
While the company has a capable engineering team, it lacks hands-on experience in building production-grade AI systems. This is where the FDE engagement begins, stepping in to guide the team from initial planning to a fully functional, scalable solution.
Phase 1: Production readiness and architecture (Weeks 1–3)
The first phase focuses on understanding the client’s environment and designing an architecture that works within real-world constraints.
At this stage, forward-deployed engineering operates in close collaboration with internal teams to define how the system should be structured for production. Hope AI plays a key role early in this process by accelerating system design and architecture planning. Teams often use Hope AI to generate initial system proposals, including component structures and service layouts. For an AI-powered application, this may include outlining data pipelines, model-serving layers and API components.
These outputs are not treated as final. Instead, FDE teams review and refine them to meet production requirements such as scalability, reliability and seamless integration with existing systems. This approach allows teams to move faster in the early design phase while still ensuring production-grade quality.
FDE engineers typically begin with a production readiness audit, examining infrastructure, deployment pipelines, security requirements and existing data systems.
In one such engagement, it was discovered that the client already had machine learning models built internally. The initial assumption was that model accuracy was the issue. However, the real challenge was the lack of a reliable system for deploying and scaling those models in production.
This is a common pattern in AI projects. According to Gartner, only about 48 percent of AI initiatives successfully transition from prototype to production, often due to gaps in infrastructure and operational readiness.
During this phase, the FDE team works alongside client engineers to map out the system architecture required to support the AI application. This typically includes:
- Data ingestion pipelines
- Feature processing layers
- Model serving infrastructure
- API services
- Monitoring and logging systems
Internal engineers are deeply involved throughout. They review architectural proposals, share infrastructure constraints and help shape integration decisions.
For example, a client team may require all services to run within an existing Kubernetes cluster. Such constraints directly influence architectural decisions and system design.
Over time, this collaborative process helps internal teams build a library of reusable patterns. These patterns continue to support development even after the engagement ends, enabling teams to extend systems and introduce new features independently.
Phase 2: Collaborative build (Weeks 4–8)
Once the architecture is defined, the engagement moves into the development phase.
This stage is intentionally collaborative. The goal is not for the FDE team to build the system in isolation, but to work alongside the client’s engineers so they can learn how the architecture functions in practice.
Hope AI continues to support this phase by assisting with early-stage implementation planning, generating component-level suggestions and accelerating how teams approach system design decisions. However, as in Phase 1, all outputs are reviewed and adapted by engineers to ensure they meet production standards.
In the early weeks, FDE engineers typically lead the implementation of core infrastructure, including:
- Model serving systems
- Data ingestion pipelines
- Monitoring and observability tools
- Authentication and access control layers
As the phase progresses, responsibility gradually shifts toward the client team.
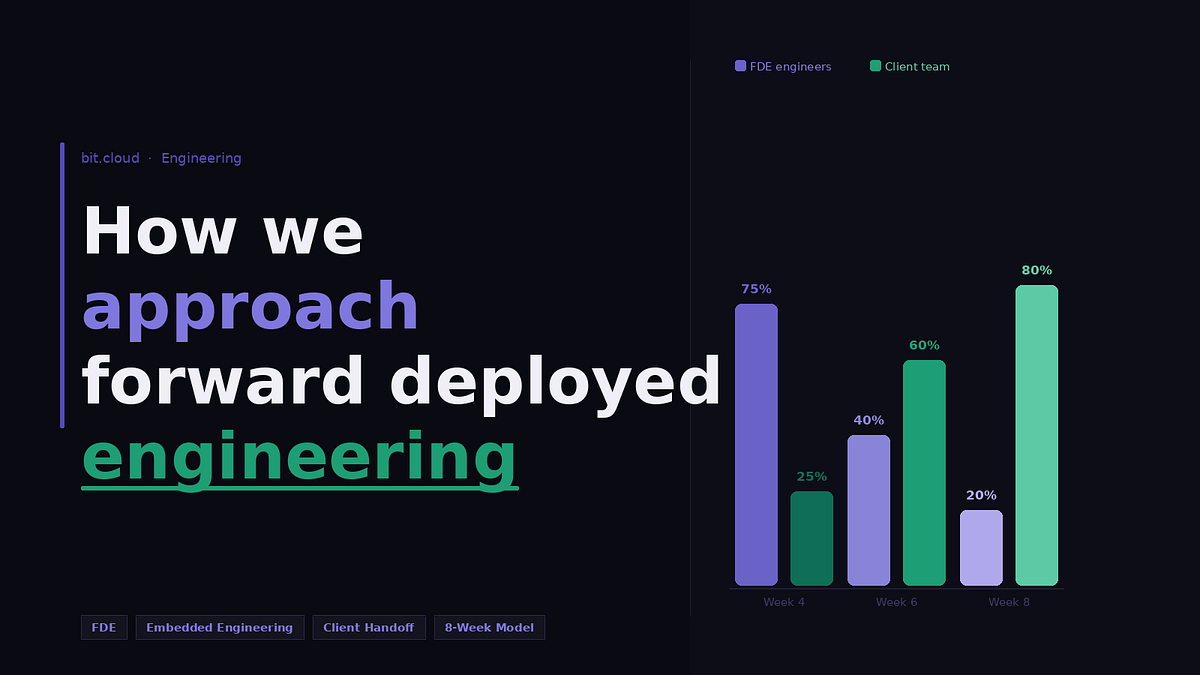
Press enter or click to view image in full sizeResponsibility shifting from FDE to client
- Week 4: FDE engineers contribute the majority of the code, with limited input from client engineers.
- Week 6: Client engineers begin building full features, while FDE teams focus more on architectural guidance and production patterns.
- Week 8: The client team takes on most of the feature development, with FDE engineers acting primarily as reviewers and mentors.
This gradual transition is critical. It ensures that internal teams not only understand the system but can actively contribute to its development.
Challenges often emerge during this phase, particularly as systems are tested under real conditions. In one engagement, the document processing pipeline struggled to handle spikes in incoming data.
The issue was resolved by introducing a queue-based processing system, enabling horizontal scalability and improved reliability.
These moments are valuable learning opportunities. They demonstrate how production systems evolve under real constraints and help internal teams build confidence in handling similar challenges independently.
Phase 3: Client-led delivery (Weeks 9–12)
In the final phase, ownership fully transitions to the client’s internal team.
By this stage, the core system is in place and engineers are equipped with the knowledge and experience needed to operate and scale it. The focus shifts to feature completion, system testing and preparing for production deployment.
Client engineers take the lead in implementing remaining features and integrating the platform with internal systems. This may include building AI-driven workflows such as automated document classification and tagging.
The FDE team steps back into a supporting role, focusing on:
- Reviewing pull requests
- Validating architectural and performance decisions
- Providing guidance during final production preparations
Deployment is handled by the client team, with FDE engineers ensuring stability and readiness through reviews and feedback.
By the end of the engagement, the AI platform is fully operational in production. More importantly, the internal team is now capable of maintaining, scaling and extending the system independently.
How participation actually shifts
One of the core promises of forward-deployed engineering is that the client team ultimately owns the system. For technical leaders evaluating this model, that promise naturally raises an important question: How does ownership actually develop over time?
In practice, ownership is not transferred at the end of the engagement. Instead, it is built gradually. The FDE team does not operate in isolation and then hand over a finished product. Internal engineers are involved throughout the process, increasing their contribution and responsibility step by step.
The shift becomes clearer when viewed across key stages of the engagement:
1. Week 4: Client reviews architecture
By week four, development is underway and the system architecture is beginning to take shape. At this stage, FDE engineers primarily focus on implementing core infrastructure components required to support the system.
Get Hamnaghufran’s stories in your inbox
Join Medium for free to get updates from this writer.
Remember me for faster sign in
For an AI platform, this typically includes:
- Model serving infrastructure
- Data integration pipelines
- API layers
- Monitoring and logging systems
FDE teams lead this phase because building foundational systems requires deep production engineering experience. During this period, internal engineers actively participate by reviewing architectural decisions, understanding system design and aligning implementations with internal constraints.
At this stage, internal teams typically contribute a smaller portion of the codebase, while most effort is concentrated on complex infrastructure components.
With collaboration, studies show that teams can deliver software 208 times more frequently and with significantly faster recovery times.
2. Week 6: Client builds feature logic
By the midpoint of the engagement, participation begins to shift more noticeably toward the client’s engineering team.
Internal engineers start implementing significant portions of the application logic. Rather than contributing small components, they take ownership of complete features within the platform.
At the same time, the role of the FDE team evolves. Instead of leading most of the implementation, they focus on reviewing pull requests, validating architectural decisions and guiding production engineering practices.
Code reviews become a central mechanism for collaboration. They improve code quality and serve as a practical way to transfer knowledge between teams. This is a key reason why forward-deployed engineering emphasizes collaborative development over isolated delivery.
3. Week 8: Client implements entire features
By week eight, the balance of development has shifted substantially.
Internal engineers are now capable of implementing entire features independently. Through hands-on involvement, they gain a deeper understanding of system architecture, component interactions and how application logic integrates with AI models.
This phase is critical for capability building. Engineers learn not only by observing but by actively solving problems. When challenges arise, the FDE team provides guidance, helping refine solutions and reinforce best practices.
As a result, internal teams become increasingly confident in managing and evolving the system on their own.
4. Week 10: Client deploys to staging
At this stage, ownership has largely transitioned to the client team.
Internal engineers take responsibility for deploying the system to staging environments. This includes configuring infrastructure, running integration tests and preparing for production rollout.
The FDE team remains involved, but in a supporting capacity. Their focus shifts to validating production readiness, reviewing deployment processes and ensuring system stability.
At this point, the distinction is clear: The client team executes, while the FDE team guides and reviews. This stage effectively demonstrates whether the internal team is ready to operate the system independently.
Why participation increases over time
Forward-deployed engineering engagements are intentionally structured to increase internal team participation over time. The goal is to build long-term capability through direct involvement in the full development lifecycle.
By the end of the engagement, internal teams typically have:
- Implemented major features
- Resolved production-level engineering challenges
- Managed deployments independently
Ownership, therefore, is not introduced as a final handoff. It emerges naturally as a continuation of the work internal engineers have been performing throughout the engagement.
A final review consolidates these outcomes, ensuring the team has a clear understanding of both the system and the processes required to sustain and extend it.
What Hope AI actually does
Forward-deployed engineering focuses on building production systems in collaboration with internal teams. Hope AI supports this process by accelerating how teams design and structure systems during the engagement.
Teams often use Hope AI during the architecture and development phases to generate initial system proposals and component structures.
For example, when teams build an AI-powered application, Hope AI can outline the services required to support the system, including data pipelines, model-serving layers and API components.
Engineers do not treat these outputs as final architecture. Instead, forward-deployed engineering teams review and refine them to meet production requirements, including scalability, reliability and integration.
Internal engineers typically participate in this process. They learn design patterns for building scalable AI systems by reviewing and implementing the proposed architecture.
Over time, teams build a library of reusable patterns that support future development. After the engagement ends, these patterns enable internal teams to extend systems and introduce new features.
In practice, Hope AI accelerates early-stage design, while engineering teams focus on preparing systems for production.
What teams can do after the engagement
The real test begins once the internal team takes full control of the system without external oversight. At this stage, the focus shifts from guided collaboration to independent execution, where teams apply what they learned during the engagement.
In practice, client teams often demonstrate the following capabilities:
1. Building new features without external support
A clear indicator of a successful engagement is the team’s ability to extend the system without external support.
Many organizations begin with a single AI use case, such as document classification or predictive analytics. Once the platform is in place, internal teams expand its capabilities based on evolving needs.
This often includes:
- Adding new AI prediction pipelines
- Expanding data ingestion workflows
- Building internal tools on top of platform APIs
Because the team participated in building the original system, they understand how the architecture works and can confidently build on top of it.
2. Deploying system updates independently
Teams also gain the ability to manage deployments on their own.
In many organizations, deployment (not development) creates the biggest challenges, especially for AI systems. Through hands-on involvement during the engagement, teams learn how to handle deployment workflows, avoid common issues and maintain system stability.
Over time, organizations move from relying on external support to running deployments internally. This aligns with models such as build-operate-transfer, where external teams initially build and support the system before transitioning full operational responsibility to internal teams.
3. Onboarding new engineers
Engineering teams evolve constantly, with new developers joining and existing members transitioning out. Studies show that the average tenure for engineers in the technology industry is roughly one to three years.
This makes effective onboarding critical.
When teams build systems collaboratively, they also develop shared architectural understanding and standardized practices. These become part of the organization’s internal knowledge base.
As a result, new engineers can onboard more efficiently using:
- Documented architecture patterns
- Reusable service templates
- Standardized deployment workflows
- Established development practices
Internal teams no longer depend on external consultants to explain how systems work. Instead, they transfer knowledge directly based on firsthand experience.
4. Continuing AI development internally
In many cases, the initial engagement becomes a foundation for broader AI adoption.
After successfully deploying the first system, internal teams begin exploring additional AI use cases and expanding existing capabilities. AI development rarely remains a one-time effort; it evolves as organizations identify new opportunities.
This is important because AI development rarely happens as a one-time project. Even research shows that around 42 percent of companies are actively deploying AI in their operations, while many others are still experimenting or scaling their AI initiatives.
Because teams actively participated in building and scaling the initial system, they can continue developing new AI initiatives without relying on external engineering support.
Build systems your team can own
Companies often bring in external teams to build critical systems to save time and accelerate delivery. However, this approach creates problems later when internal engineers need to maintain and extend systems they did not help build.
Forward-deployed engineering avoids this gap by involving internal engineers throughout the entire process. Teams do not receive a finished system at the end. Instead, they actively participate in building it, understanding the architecture, infrastructure and design decisions as they take shape.
By the time the system reaches production, internal engineers already understand how it works and what it requires to operate and scale. Ownership develops alongside the system rather than appearing as a final handoff.
Platforms such as Bit Cloud support this approach by enabling component-driven system design. Teams can move from early feasibility to scalable systems while maintaining clarity around how each part fits together.
The result stays practical: Teams build systems and retain the ability to run and evolve them.



